This analysis was co-authored by data scientists, Scott Fisher and Douglas Davila-Pestana. Mr. Fisher developed the Python code for the analysis, and Mr. Davila-Pestana developed the R and Julia code for the analysis.
Miami-Dade County Employee Pay: A Comprehensive Data Analysis for Better Transparency
Miami is known for its beaches and its warm weather all year round. There are over 2.6 million people living in sunny Miami-Dade County, Florida (according to the US Census Bureau), and it’s the largest county in Florida in terms of population. It has a two-tier system of government: city and county. The city government is the first tier, providing local services like police and fire protection, and enforcing city codes, and there are 34 municipalities in Miami-Dade County. Each city, including the largest one, the City of Miami, pays for these services with its own city taxes. The county government is the second tier, handling metropolitan services such as running airports and seaports, emergency management, providing public housing and healthcare, transportation, environmental services, and disposing of solid waste. These services are funded by county taxes.
As such, the county government plays an important role in serving the public, and the Miami-Dade County Government contains numerous departments and employs thousands of employees.
Have you ever wondered how government employee salaries compare across departments, roles, and against national averages? We’ll explore the latest employee pay data from Miami-Dade County for a deep dive into these questions. The dataset we’ll look at is public data from opendata.miamidade.gov which was last updated on February 22, 2023.
Transparency is a cornerstone of republic governance and trust-building between citizens and their government. With this in mind, we delve into this open, public data. Unraveling the details of this data not only increases transparency but also allows us to evaluate the efficiency of how taxpayer dollars are allocated.

A Closer Look at Departments and High Salaries
The dataset comprises salary information from employees of various Miami-Dade County departments. Using this data, we can calculate several statistical summaries by job title and department name, including:
- employee count
- average and median salaries
- salary standard deviation
- salary percentiles
- total sum of department salaries
- department’s ranking by median salary
- department’s ranking by employee count
- Budget Bloat Composite Score Rank – a composite score ranking that signals the department has a high count of employees with high median salaries
Here are a few metrics about Miami-Dade County Government employees based on those summaries:
- Average Salary is $75,722
- Median Salary is $69,562
- There are 45 government departments
- There are 29,407 employees
- The total annual salary budget is $2.22B
For comparison purposes, the median household income of everyone who lives in Miami-Dade County is $57,815, according to the US Census Bureau. Similar median household income figures can be found from the Federal Reserve Economic Data. And that’s household income, which means it’s the combined income total of everyone living in the household. This means that a single Miami-Dade County government employee has a median salary that is 20% higher than the median household income of residents living in Miami-Dade County.
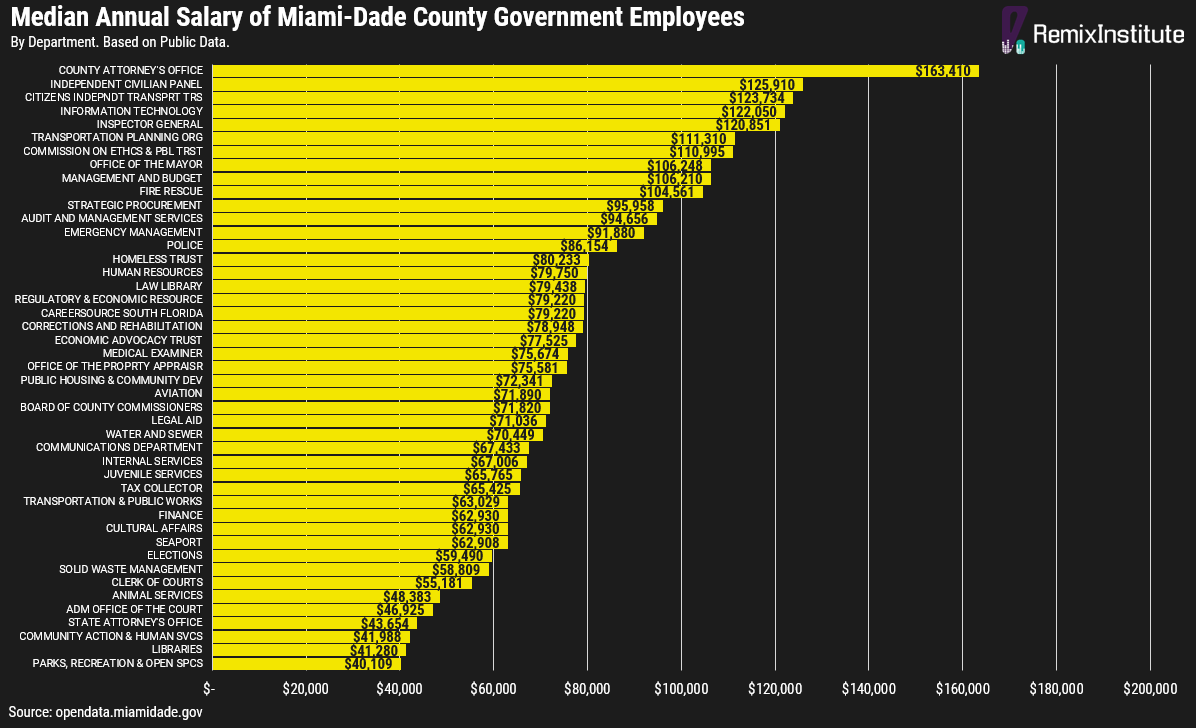
The top 5 departments with the highest median salaries are the County Attorney’s Office, Independent Civilian Panel, Citizens Independent Transportation Trust, Information Technology, and Inspector General department. These top 5 departments all have a median salary of $120,000 or higher. 10 out of the 45 government departments have a median salary of $100,000 or more. You can view the median salary by department in the chart below:
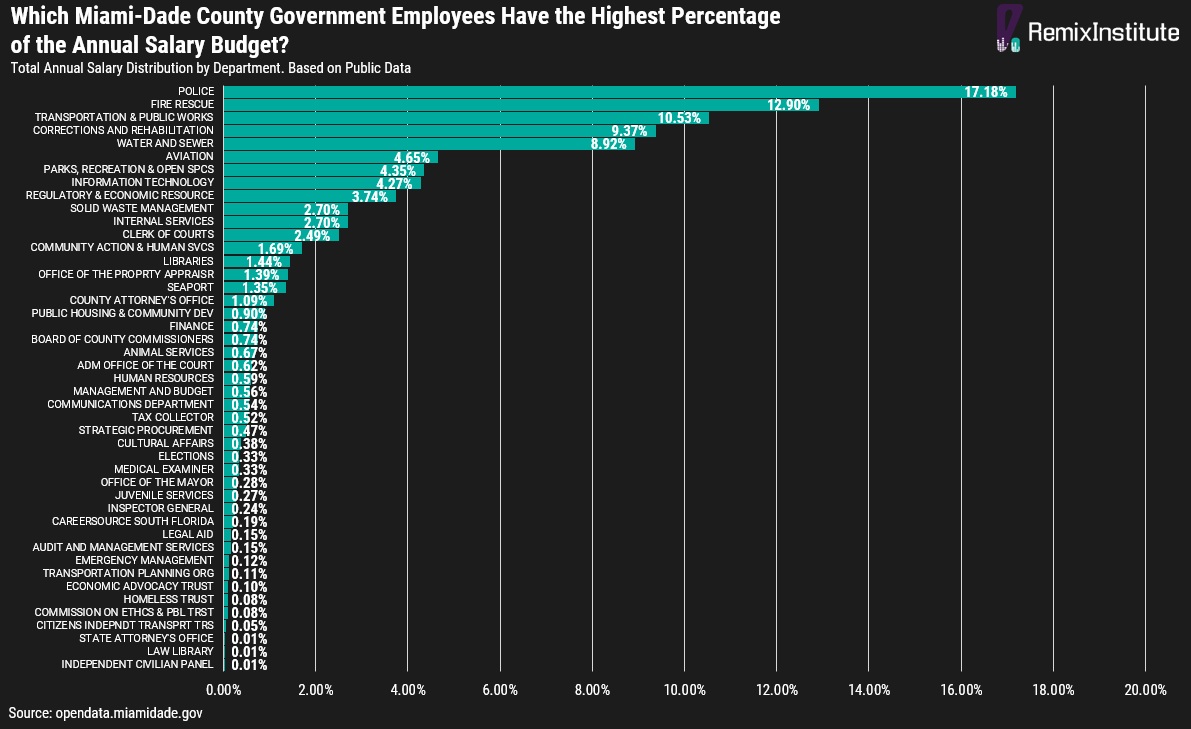
There’s only a few departments of the Miami Dade-County government which make up the majority of the annual salary budget. The top 2 departments which make up the largest percent of the annual salary budget are the Police department and Fire Rescue department, which combined comprise almost 1/3 of the total annual salary budget (30%). The top 6 departments comprise almost 2/3 of the total annual salary budget (64%): Police, Fire Rescue, Transportation and Public Works, Corrections and Rehabilitation, Water and Sewer, and Aviation.
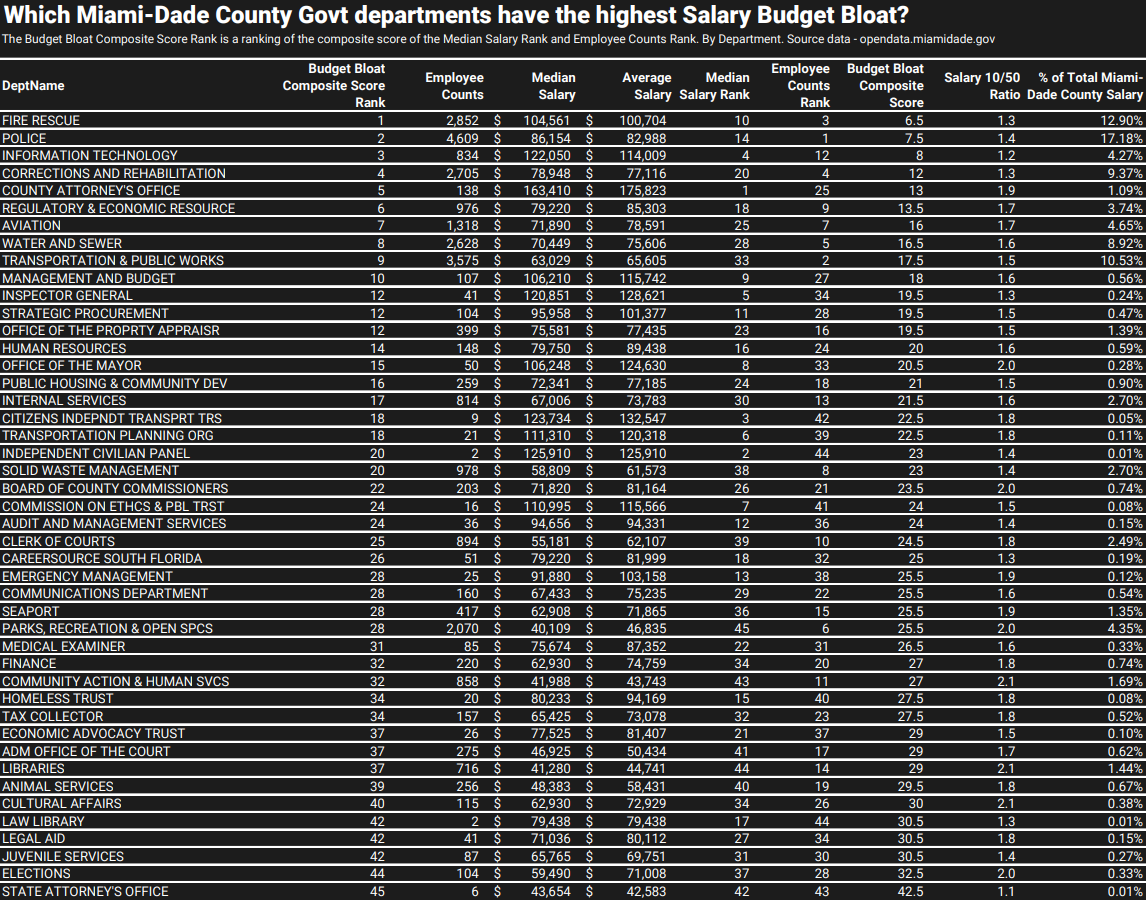
Departments with high count of employees and with high median salaries are going to have the highest salary budget bloat. That’s where we calculated the Budget Bloat Composite Score Rank that was discussed previously in the article. Based on the Budget Bloat Composite Score Rank, the top 5 departments with the highest salary budget bloat are: Fire Rescue, Police, Information Technology, Corrections and Rehabilitation, and County Attorney’s Office.
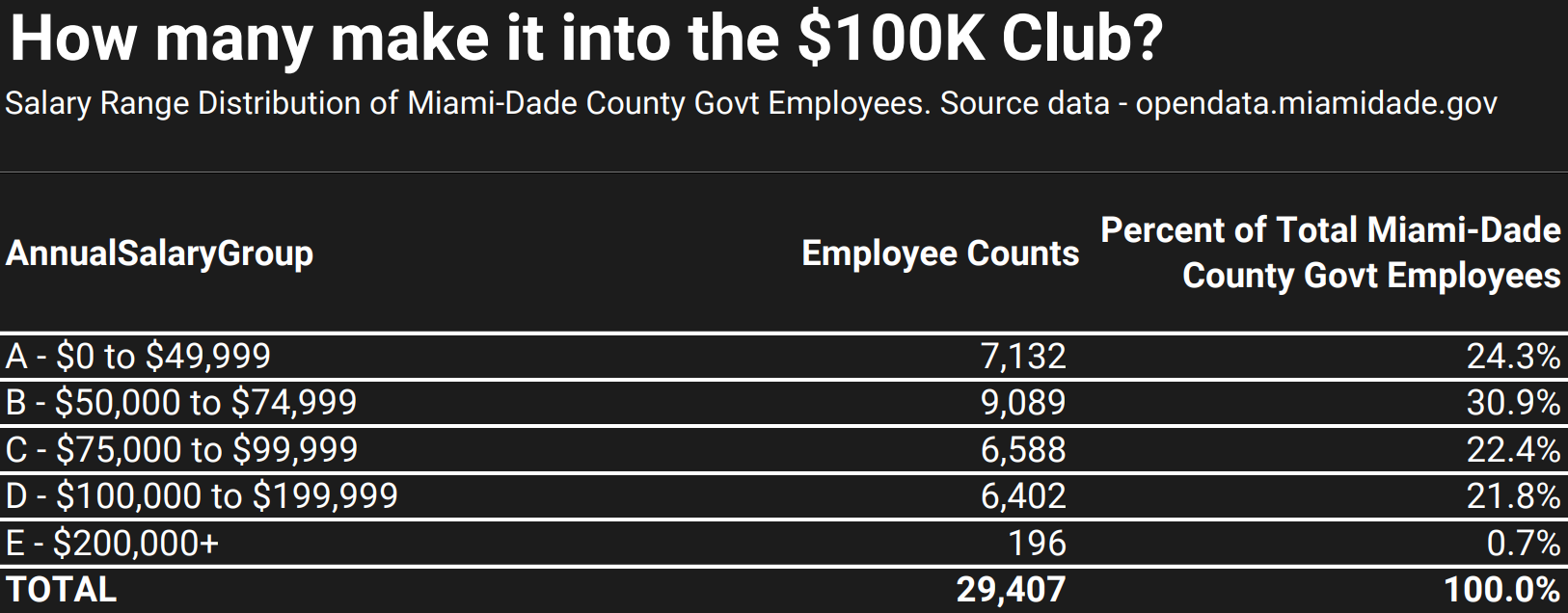
The $100K Club
We also analyzed how many government employees for Miami-Dade County make over $100,000 annually. The figure stands at 6,598, representing 22% of the total 29,407 Miami-Dade County government employees. This shows that while a six-figure salary is not uncommon, it’s only a reality for a minority of employees.
Top Paid Positions
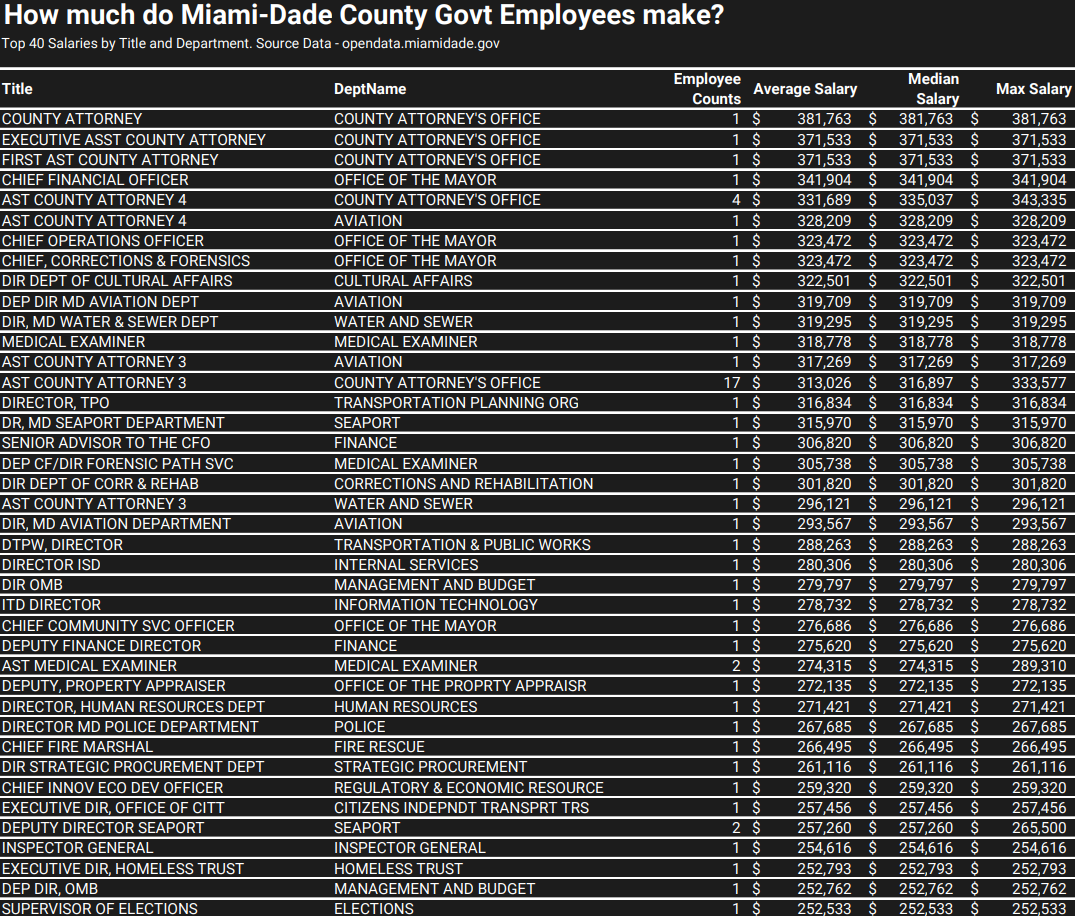
We also examined the highest-paid roles across the Miami-Dade County government. Of the total unique 3,290 job positions, the top 96 positions emerged as having the highest median salaries of $200,000 or more per year. These lucrative roles are not confined to specific departments. The table below shows the top 40 annual median salaries by title and department name.
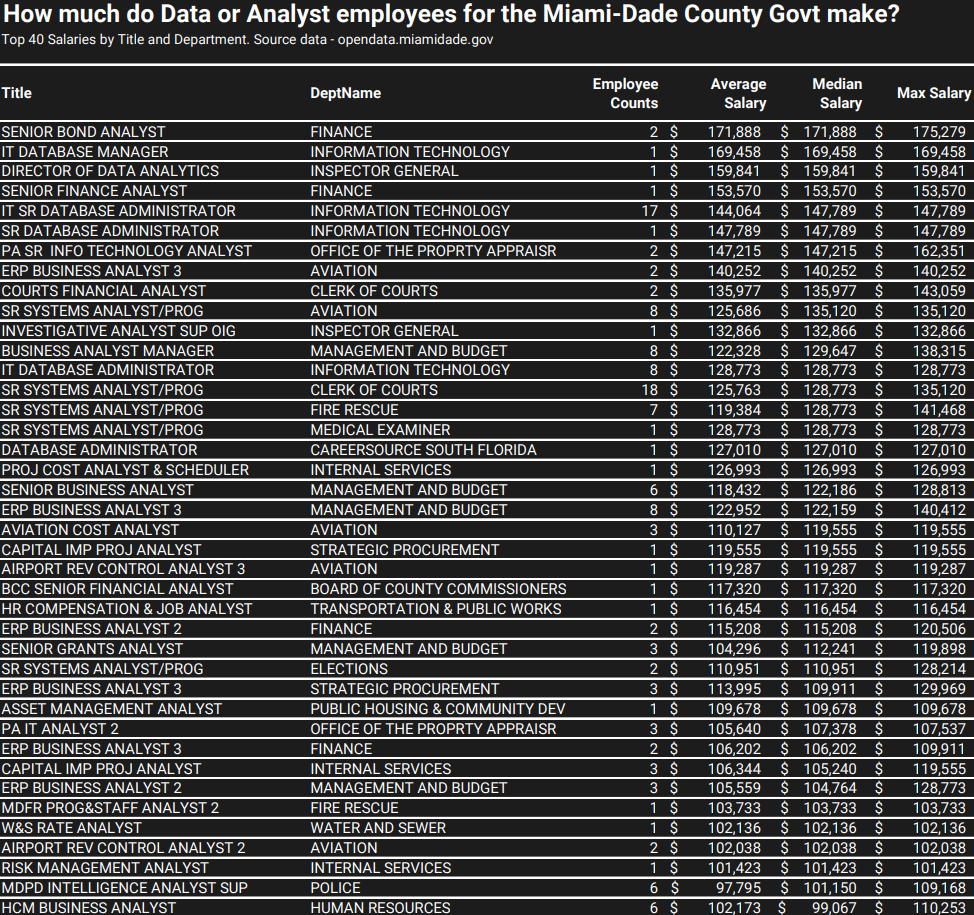
Average Salaries of Data and Analyst Positions
Data and analyst roles have been garnering increased attention in the media due to their pivotal role in driving insights, supporting optimal decision-making, and developing AI-based solutions. Our analysis found that these roles earn an average of $91,126 as an employee in the Miami-Dade County government. The table below shows the top 40 annual median salaries by department for job titles with the word “data” or “analyst” in its name.
Salary Comparisons with National, State, and City Averages
Comparing the salaries within the Miami-Dade County government to overall national, state, and city averages offers a broader perspective.
For instance, the average attorney working for the Miami-Dade County government earns $219,297, which is over $100,000 higher than the Miami city average from Payscale of $91,573 and the Miami city average from Glassdoor of $103, 515.
Similarly, the average Police Officer working for the Miami-Dade County government earns $90,098, if you look at the table by Title and Department above. This is over $15,000 higher than both the Florida state and national average Police Officer salaries of $73,350 and $71,380 respectively, according the US Bureau of Labor Statistics.
The average Firefighter working for the Miami-Dade County government earns $96,744, if you look at the table by Title and Department above. This is over $40,000 higher than both the Florida state and national average Firefighter salaries of $56,560 and $56,310 respectively, according to the US Bureau of Labor Statistics.
It’s worth noting that some of these salaries, particularly within the police and fire rescue departments, may be higher due to the influence of labor unions such as the South Florida Police Benevolent Association (PBA) and the Metro-Dade Firefighters Local 1403. These unions often negotiate for better pay, benefits, and working conditions for their members. In fact, the South Florida PBA represents the following units: Miami-Dade Police Department, Miami-Dade County Department of Corrections and Rehabilitation, Commission on Ethics and Public Trust Employees, and Miami-Dade Animal Services. The presence of police and firefighter unions in Miami-Dade County could contribute to higher-than-average salaries for these roles, a factor that is important to consider when comparing salaries across different regions and sectors.

“Peasant” Labor: Income Inequality Within Departments
An intriguing facet of our analysis is the income inequality metrics we calculated: the 20/20 ratio, the Palma ratio, the 10/50 ratio, and the Coefficient of Variation.
Let’s break down these inequality metrics in layman’s terms:
- 20/20 Ratio: This metric compares the top 20th percentile salary to the bottom 20th percentile salary within a department. If the 20/20 ratio is significantly greater than 1, it suggests that higher earners in the department make much more than the lower earners, indicating wage disparity.
- Palma Ratio: Similar to the 20/20 Ratio, the Palma Ratio compares the top 10th percentile salary to the bottom 40th percentile. This metric focuses more on the disparity between the very top earners and the middle band.
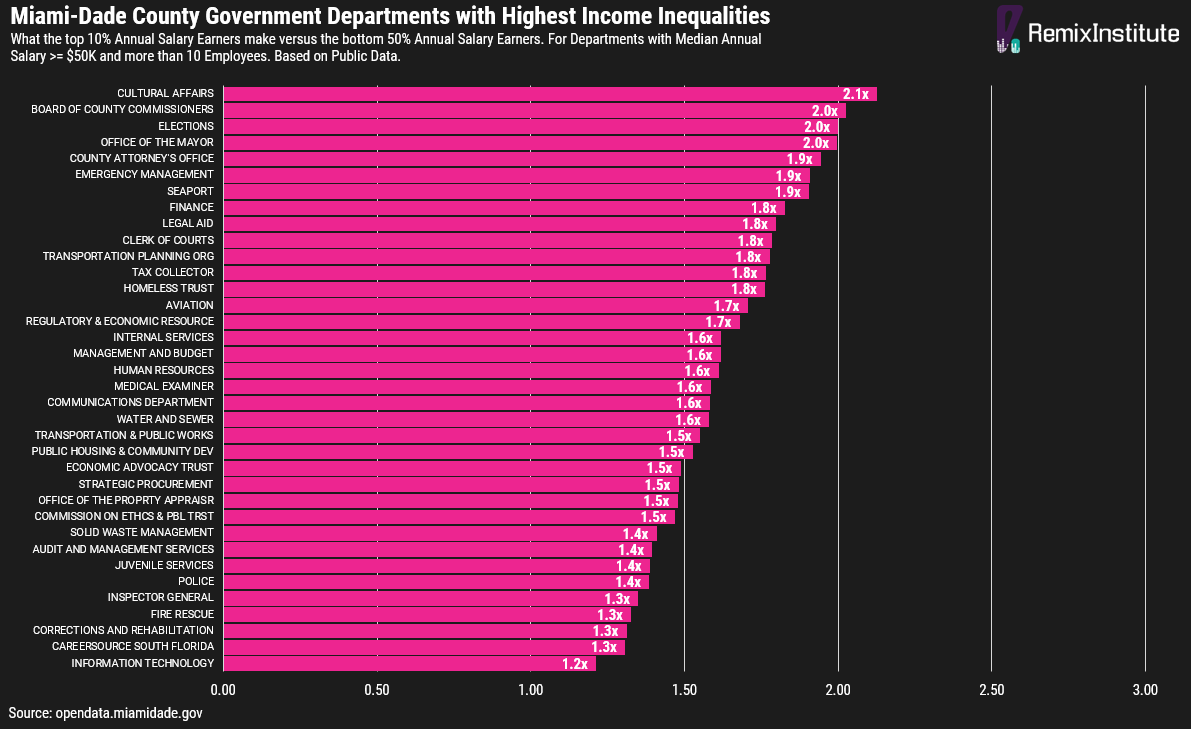
- 10/50 Ratio: Similar to both the 20/20 Ratio and the Palma Ratio, this metric compares the top 10th percentile salary to the bottom 50th percentile salary within a department. If the 10/50 ratio is significantly greater than 1, it suggests that very top earners in the department make much more than the median earner, indicating significant wage disparity. The 10/50 Ratio is what is displayed in the chart below.
- Coefficient of Variation (CV): The CV is the ratio of the standard deviation of the salaries to their mean. A higher CV indicates more significant disparity in the salary range, while a lower CV shows more uniformity.
These metrics provide a robust picture of income distribution within each department, highlighting areas of wage disparity that may warrant further investigation. The departments towards the top of the list may mean that the bottom 50th percentile of employees there may be treated as peons or “peasant” labor. The top 5 departments with the highest income inequality among employees in that department are: Cultural Affairs, Board of County Commissioners, Elections, Office of the Mayor, and the County Attorney’s Office. In these departments, the top 10% of earners make about 2x more than the bottom 50% of earners.
Concluding Thoughts
In conclusion, delving into public salary data reveals vital insights about income distribution, wage disparity, and overall payroll spending within the Miami-Dade County government. Increased transparency and careful analysis of these data points can lead to better accountability and more effective use of taxpayer dollars. Ensuring equitable wage distribution and efficient allocation of public funds is an ongoing process, and openness of data plays a crucial role in facilitating this endeavor.
Remix Institute Membership
If you liked this article, join our free Membership as a Stádas Genesis member for access to exclusive courses on getting started with R, Julia, data science, and AI. Elevate your skills and gain an edge in the industry. Sign up now for an elite learning experience.